Fw: [分享] 因flux2與Z-image新玩具/首次安裝ComfyUI
※ [本文轉錄自 AI_Art 看板 #1fArg07P ]
作者: avans (阿緯) 看板: AI_Art
標題: [分享] 因flux2與Z-image新玩具/首次安裝ComfyUI
時間: Sun Nov 30 04:41:06 2025
多年來我一直都是忠貞的stable-diffusion-webui-forge玩家
未考慮使用舒適(ComfyUI)
其實只是因為懶得換環境(w
這次新推出的flux2與Z-image新玩具
本來還有參考在huggingface上面的FLUX.2-dev spaces專案
想在本地玩玩看
專案中是使用diffusers的Flux2Pipeline來載入模型與執行
不過不管是FLUX.2-dev-bnb-4bit還是flux2_dev_Q2_K.gguf
執行時都要耗費爆量的vram
完全無法運行
畢竟FLUX.2-dev有32B 參數
以前經驗LLM超過8B不量化
執行起來就會很吃力了
後來在reddit看到ComfyUI 8GB VRAM + 18GB RAM usage
可在300~500秒生成一張圖片
https://www.reddit.com/r/StableDiffusion/comments/1p6zmjv/
我不曉得ComfyUI是如何控制vram不會爆量
也許是model cpu offload之類的
總之我就開始了首次的ComfyUI安裝
底下介紹給有打算安裝ComfyUI的新手(我也是才玩1天而已)
1. 安裝ComfyUI
首先在ComfyUI官網有執行檔可以安裝
在github中也有打包好的可攜版本(包含python)
* 在github的README.md中也有介紹手動安裝方式
https://github.com/comfyanonymous/ComfyUI/releases
因為我是3060 12G所以我選擇
ComfyUI_windows_portable_nvidia_cu128.7z
* cu126, cu128這個是CUDA版本,12.6、12.8 or 13.0
下載後解壓縮到任意目錄中
裡面會有run_nvidia_gpu_fast_fp16_accumulation.bat 檔案
這會將模型以fp16精度方式來加速執行
品質稍微降低,不過無所謂
重要的是能降低vram用量
2. ComfyUI流程範本
之前我已知道ComfyUI執行方式
都必須透過連接節點製作對應功能的流程
不過我完全不曉得官方有內建多項流程範本
這有點驚豔到我
最新版本已經內建Flux.2 DEV了
https://i.meee.com.tw/Rq04OJB.png
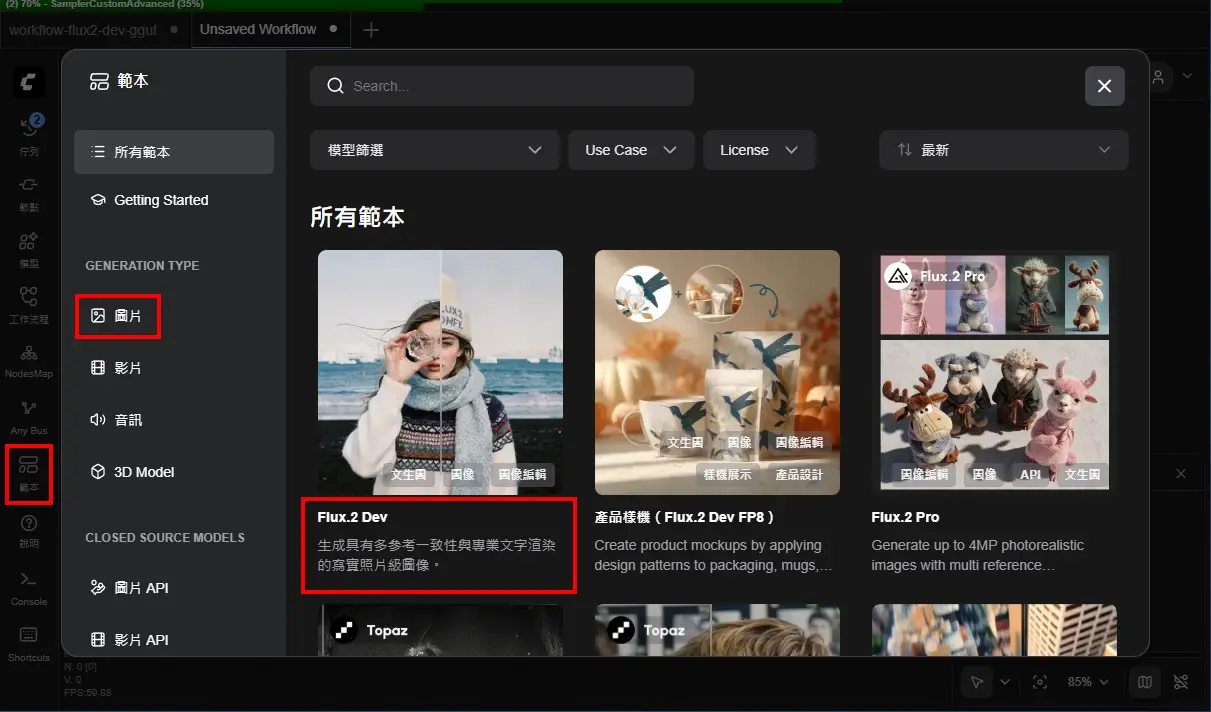
使用官方範本的好處是會顯示缺少的模型
並且可直接下載
https://i.meee.com.tw/rjv0BMT.png
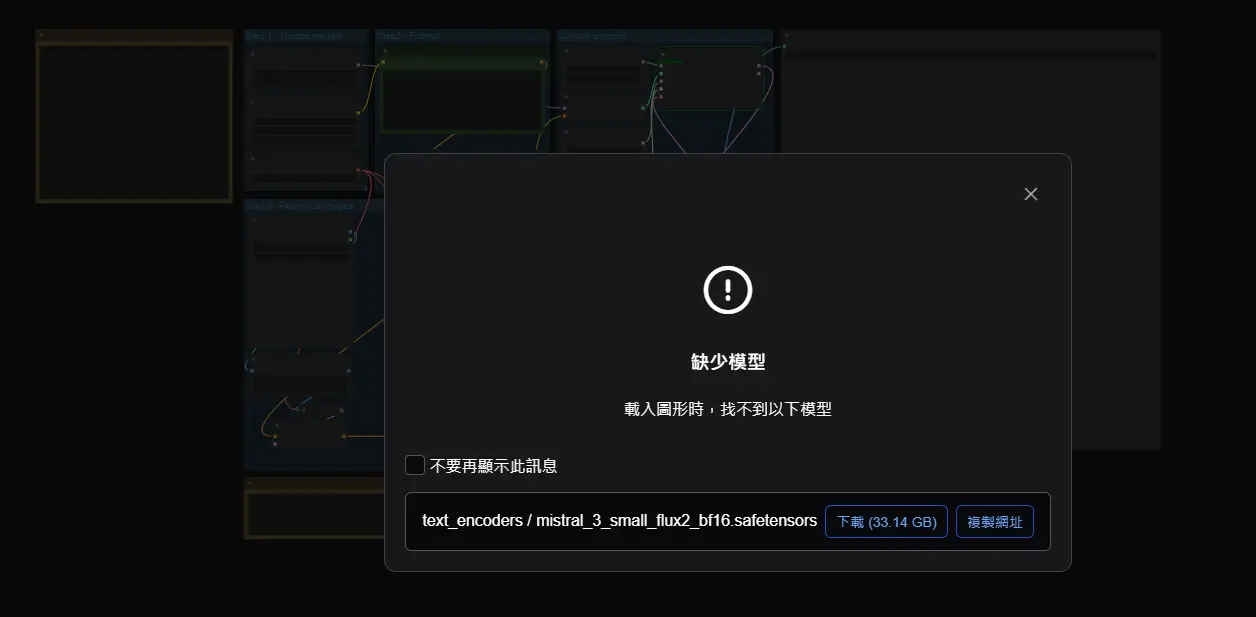
不過這個範本是使用fp8精度模型
仍需使用巨量的vram
https://i.meee.com.tw/0kMjkDe.png
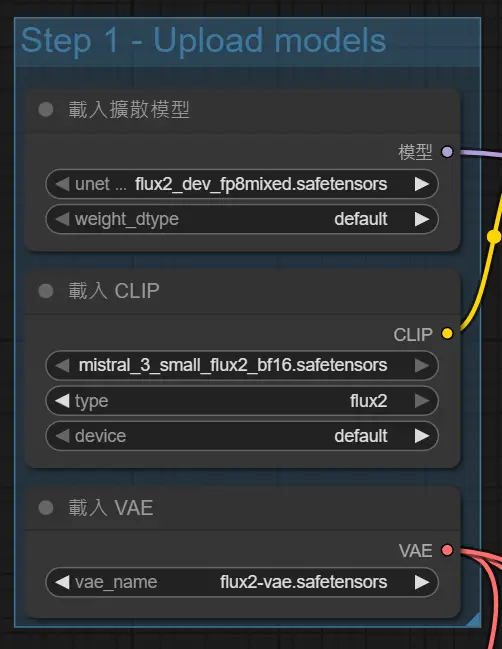
所以官方範本不適合我的環境
3. GGUF量化版本
後來在huggingface上面找到有提供flux2-dev的gguf檔案
而且連text_encoders都是gguf量化版本
更棒的是連workflow流程檔案都有
流程檔案:
workflow-flux2-dev-gguf.json
或
workflow-demo-01.png
ComfyUI生成的圖片本身都會崁入workflow
將json或圖片拖曳至ComfyUI上面就會自動顯示所需的節點
https://huggingface.co/gguf-org/flux2-dev-gguf
https://raw.githubusercontent.com/calcuis/comfy/master/flux2-dev.png
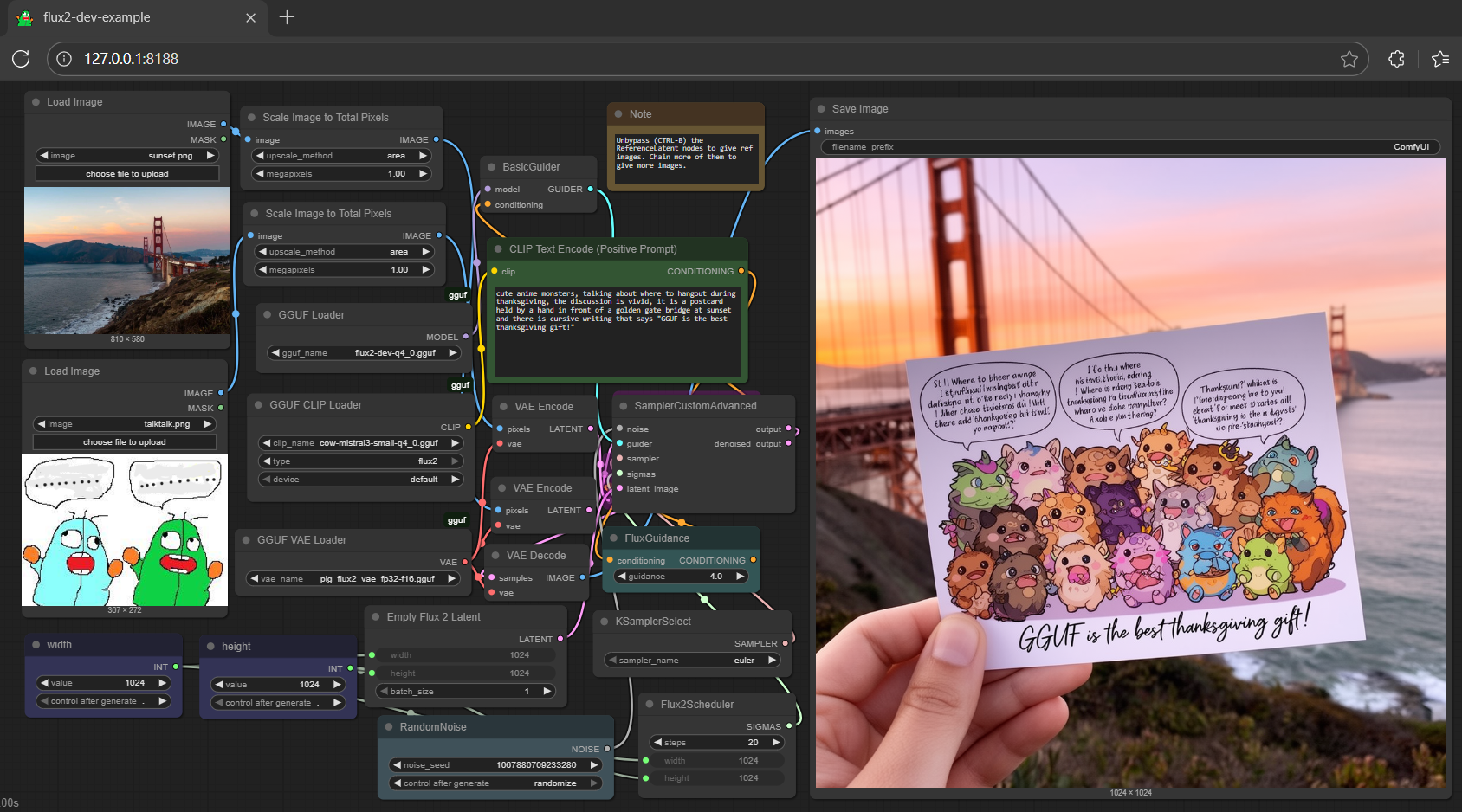
你所需要下載的檔案有3個
文字編碼器、模型檔案、vae檔案
下載後放置至對應的ComfyUI目錄
drag cow to > ./ComfyUI/models/text_encoders/
drag flux2 to > ./ComfyUI/models/diffusion_models/
drag pig to > ./ComfyUI/models/vae/
gguf量化版本有q2、q3、q4、q5、q6、q8、iq4 (詳細定義需要查一下)
我自己是下載底下三個來使用:
cow-mistral3-small-iq4_xs.gguf
flux2-dev-iq4_xs.gguf
pig_flux2_vae_fp32-f16.gguf
4. 必裝套件ComfyUI Manager
https://github.com/Comfy-Org/ComfyUI-Manager
這個我一開始不曉得要安裝
後來查詢後才知道這絕對是所有ComfyUI使用者
都需要使用的重要套件
因為workflow的節點不會只有官方版本
民間設計的節點五花八門
缺少節點就完全無法執行
甚至還存在有所謂的私有節點
以RH開頭的好像是runcomfy線上網站專用的
ex. RH_captioner、RH_LLMAPI_NODE...
如下圖例子,缺少的節點會是紅色框
https://i.meee.com.tw/9lQCHP9.png
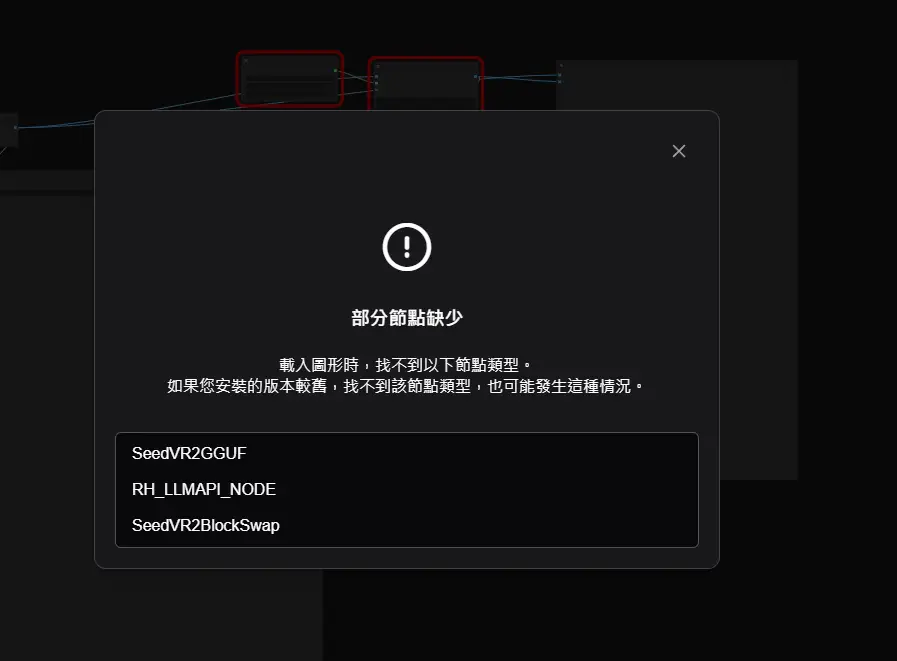
而ComfyUI-Manager就是管理節點的強大工具
在安裝該套件之前
需要確認系統已經有安裝git軟體
(git是程式開發的版控軟體)
按照README.md說明方式:
使用cmd介面移動至ComfyUI/custom_nodes的路徑,輸入底下指定後再重啟ComfyUI
git clone https://github.com/ltdrdata/ComfyUI-Manager comfyui-manager
https://i.meee.com.tw/EwJ56LX.png

重啟後會在任意流程的上方出現如下圖的介面
點選Manager按鈕後,會跳出ComfyUI Manager選單
https://i.meee.com.tw/clLhtxa.png
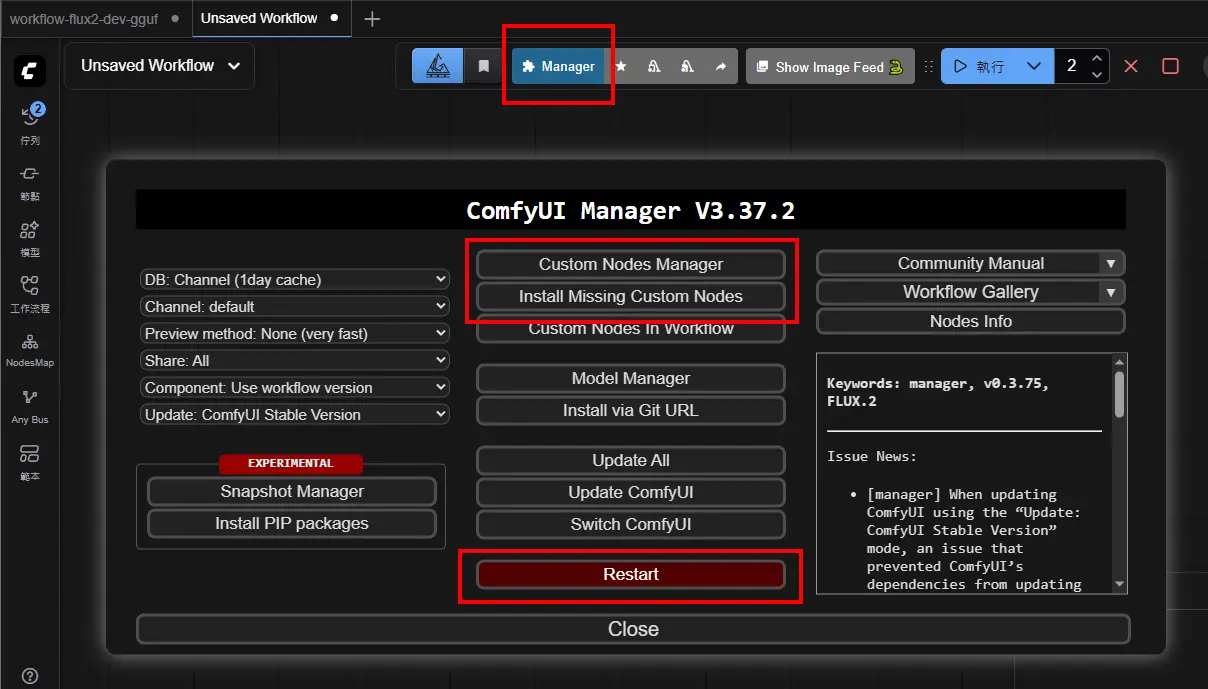
目前我只會使用底下兩個功能
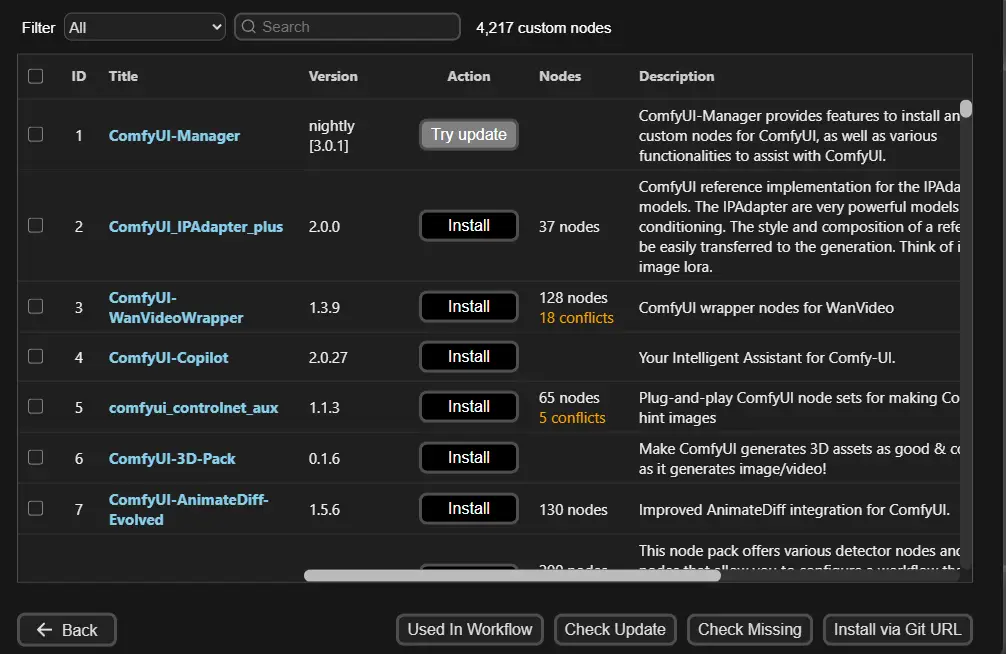
(1) Custom Nodes Manager
在此頁面中會搜尋網路上所有公開的節點
在上方也可由選單執行Filter過濾內容與搜尋特定目標
如下圖預設是All會顯示全部
https://i.meee.com.tw/HYSKruc.png
例如選擇Installed,他就會列出已安裝套件,可執行更新或移除
https://i.meee.com.tw/5MoKW16.png
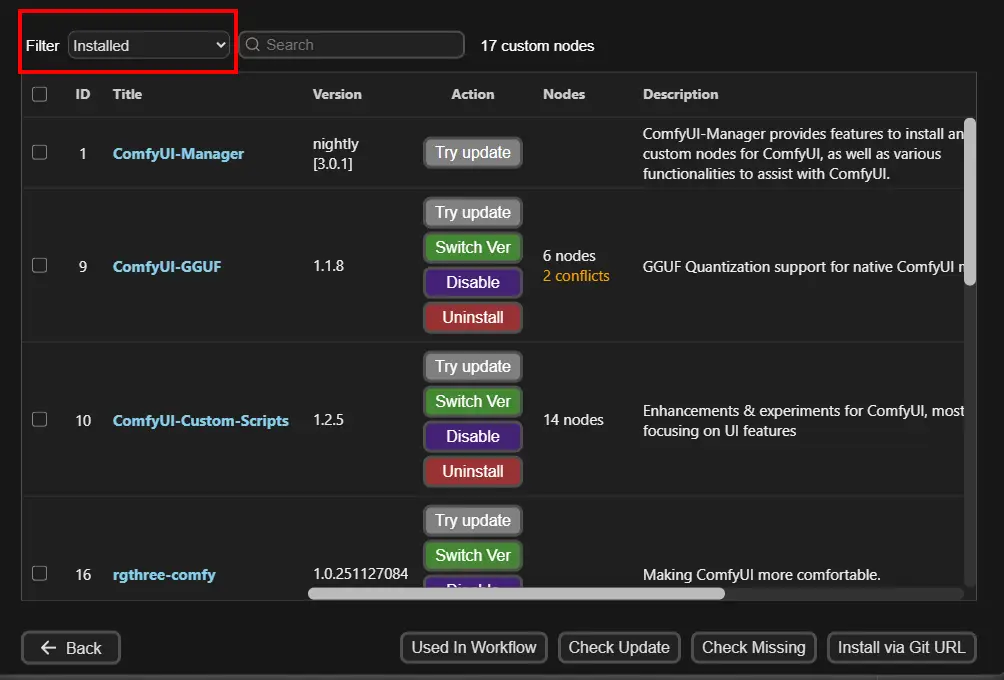
* 可看到在Nodes欄位中有的有寫數字,這個是該套件內含的節點數量
(2) Install Missing Custom Nodes
點選此按鈕後,其實出現的與上面頁面相同
只是在過濾條件中是選Missing
https://i.meee.com.tw/LyqPcuC.png
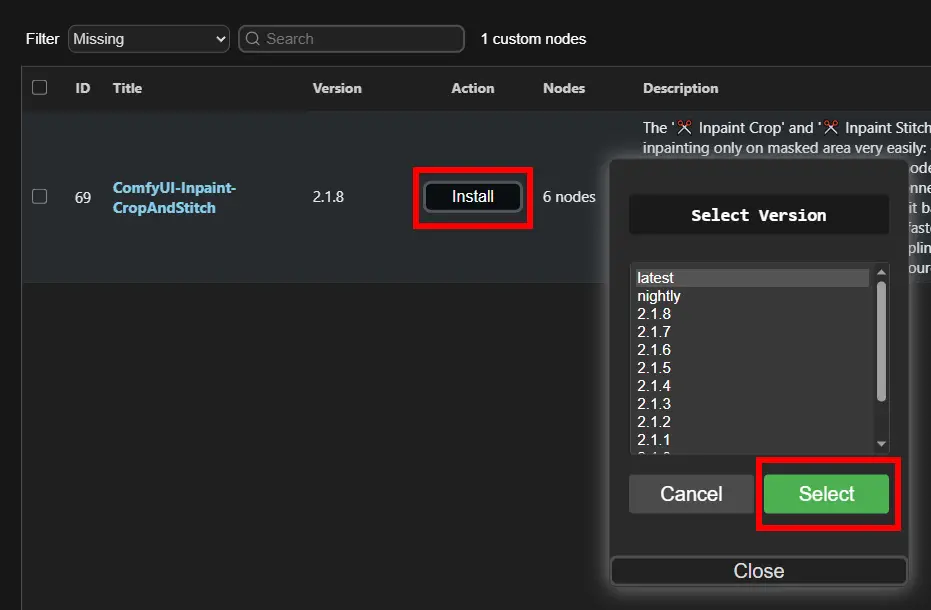
點安裝按鈕需要選擇版本,沒有喜好的話通常選最新的
安裝後需要重啟ComfyUI,節點才會生效
不過需要注意的是此功能只能找到7~9成的套件
因為有的節點名稱與套件名稱完全不同
這種就需要在網路上搜尋確認對應的套件名稱
5. 介紹一下工作流程: workflow-flux2-dev-gguf
https://i.meee.com.tw/MWuEBdt.png

(1) 參考圖
這個workflow已有設計兩個參考圖片,如果要更多參考圖就需要自行串接:
載入圖片1 => 將影像縮放至總像素數1 => VAE 編碼1 => ReferenceLatent1
GGUF VAE Loader => VAE 編碼1
載入圖片2 => 將影像縮放至總像素數2 => VAE 編碼2 => ReferenceLatent2
GGUF VAE Loader => VAE 編碼2
這裡要注意一下,圖片紅框處ReferenceLatent是紅色的
這是什麼意思? 原來作者好心(XD)幫你將參考圖功能停用了
如底下Note寫的內容,要用滑鼠點一下節點,在按CTRL+B來啟用節點
Note: Unbypass (CTRL-B) the ReferenceLatent nodes to give ref images.
Chain more of them to give more images.
我一開始也不曉得,想說參考圖怎麼都沒作用,後來才注意到被關閉了
不過啟用參考圖,執行速度也會降低,所以也不能啟用太多參考圖
(2) 正向提示詞
GGUF CLIP Loader => CLIP Text Encode (Positive Prompt) => FluxGuidance =>
ReferenceLatent1
因為CLIP是gguf量化版本,所以此處是使用GGUF CLIP Loader來載入
如果是標準的CLIP模型,就直接使用CLIPLoader
Flux2使用的Text Encode是參數非常龐大的Mistral-3 24B
本身能理解多語言,直接輸入中、日語也完全沒問題
待會還會介紹的Z-image也類似,他使用的Text Encode是Qwen3-4B
參數雖小許多,但是輸入中、日語也沒什麼問題
仔細觀察會看到ReferenceLatent1有參考圖也有Prompt
然後兩個ReferenceLatent還會串接在一起,再輸出給引導器使用
ReferenceLatent1 => ReferenceLatent2
若ReferenceLatent未啟用時(紅色)
就只會給模型輸入Positive Prompt而已
(3) 載入flux2模型與VAE
GGUF VAE Loader => VAE 解碼 => 儲存圖片
GGUF Loader => 基礎引導器 => SamplerCustomAdvanced => VAE 解碼
ReferenceLatent2 => 基礎引導器 => SamplerCustomAdvanced
因為我這裡使用的是gguf量化版本
所以節點是GGUF Loader與GGUF VAE Loader
目前GGUF有兩個套件
https://i.meee.com.tw/V6XuuCr.png
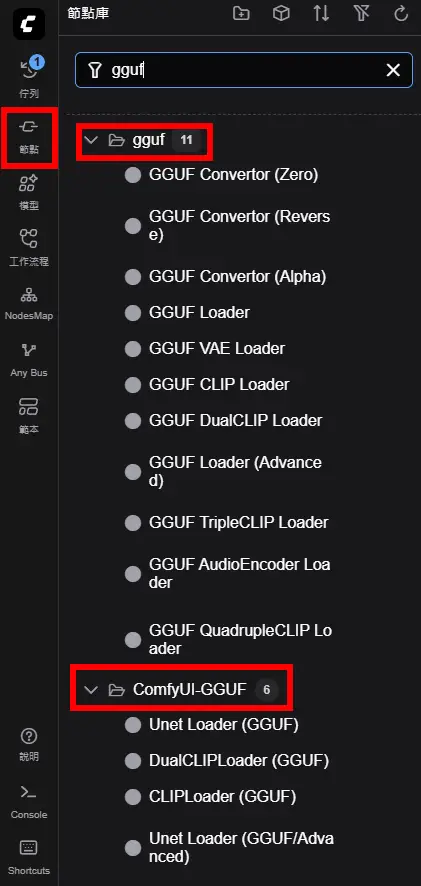
此工作流使用的是gguf
https://github.com/calcuis/gguf
(4) SamplerCustomAdvanced等節點
https://i.meee.com.tw/lUItSiB.png
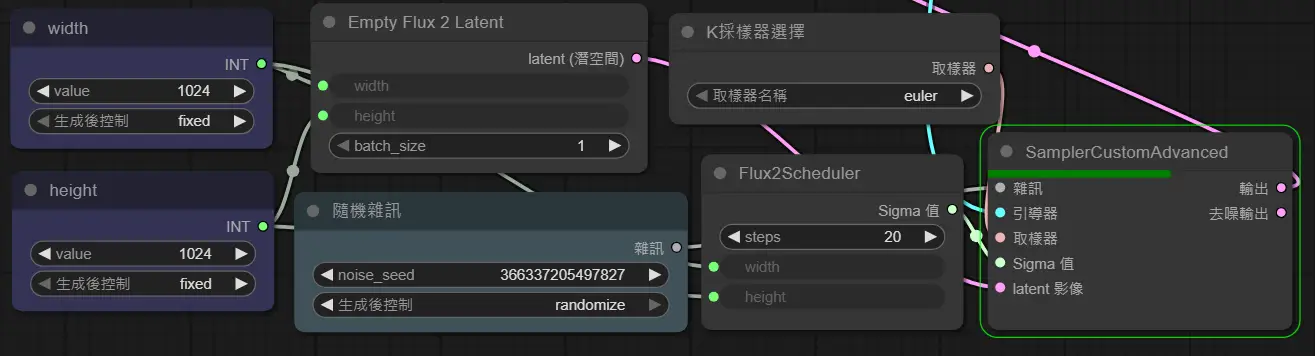
Empty Flux 2 Latent => SamplerCustomAdvanced
隨機雜訊 => SamplerCustomAdvanced
K採樣器選擇 => SamplerCustomAdvanced
Flux2Scheduler => SamplerCustomAdvanced
這幾個節點用途有玩過SD的應該都會知曉
就是設定輸出寬高、批次大小、seed、取樣器、生圖步數(steps)
(5) 執行速度
我的環境3060 12G、批次大小2、1024x1024、steps 20
每個it約30秒左右,一張圖約5分鐘
100%|███████████████████| 20/20 [09:21<00:00, 28.08s/it]
網路上看到其他人跑的速度,好像5060ti 16gb會快一倍的樣子
以上是目前玩玩flux2-dev與ComfyUI小心得
雖然出圖速度非常慢,不過能在本地玩Nano Banana也是挺有趣的
____________
再來底下介紹一下Z-image
1. Z Image Turbo模型
目前已公布的是Z Image Turbo模型,參數為6B
與FLUX.1 [dev]同樣為蒸餾模型(distilled diffusion model)
____________
https://github.com/Tongyi-MAI/Z-Image
底下是官方github中的模型介紹說明(Gemini翻譯)
Z-Image 是一款強大且高效的圖像生成模型,擁有 60 億(6B)參數。
目前共有三種變體:
Z-Image-Turbo –
Z-Image 的蒸餾版本,僅需 8 次 NFE(函數評估次數)
即可達到甚至超越領先競品的水準。
它在企業級 H800 GPU 上具備 亞秒級的推理延遲,
並能輕鬆在 16G VRAM 的消費級裝置上運行。
該模型在寫實圖像生成、中英雙語文字繪製
以及強大的指令遵循能力方面表現出色。
Z-Image-Base –
非蒸餾的基礎模型。藉由釋出此檢查點(checkpoint),
我們旨在釋放社群驅動微調與客製化開發的無限潛力。
Z-Image-Edit –
專為圖像編輯任務而基於 Z-Image 進行微調的變體。
它支援具備出色指令遵循能力的創意「圖生圖」(image-to-image)生成,
能根據自然語言提示詞進行精準的編輯。
____________
從說明中可看到Turbo版本只能文生圖,
更具實用性的圖生圖尚須等待Z-Image-Edit推出。
____________
2. 模型與workflow
Turbo版本模型檔案與workflow都在底下網頁中可下載
ComfyUI_examples
https://comfyanonymous.github.io/ComfyUI_examples/z_image/
同樣要下載文字編碼器、模型檔案、vae檔案
下載後一樣要放置至對應的ComfyUI目錄
Text encoder file: qwen_3_4b.safetensors
(goes in ComfyUI/models/text_encoders/).
diffusion model file: z_image_turbo_bf16.safetensors
(goes in ComfyUI/models/diffusion_models/).
VAE: ae.safetensors the Flux 1 VAE if you don’t have it already
(goes in ComfyUI/models/vae/)
好像也有gguf版本,不過我就沒試過了
因為一般版本跑起來輕輕鬆鬆
下圖是workflow
https://i.meee.com.tw/LoQ3SYF.png
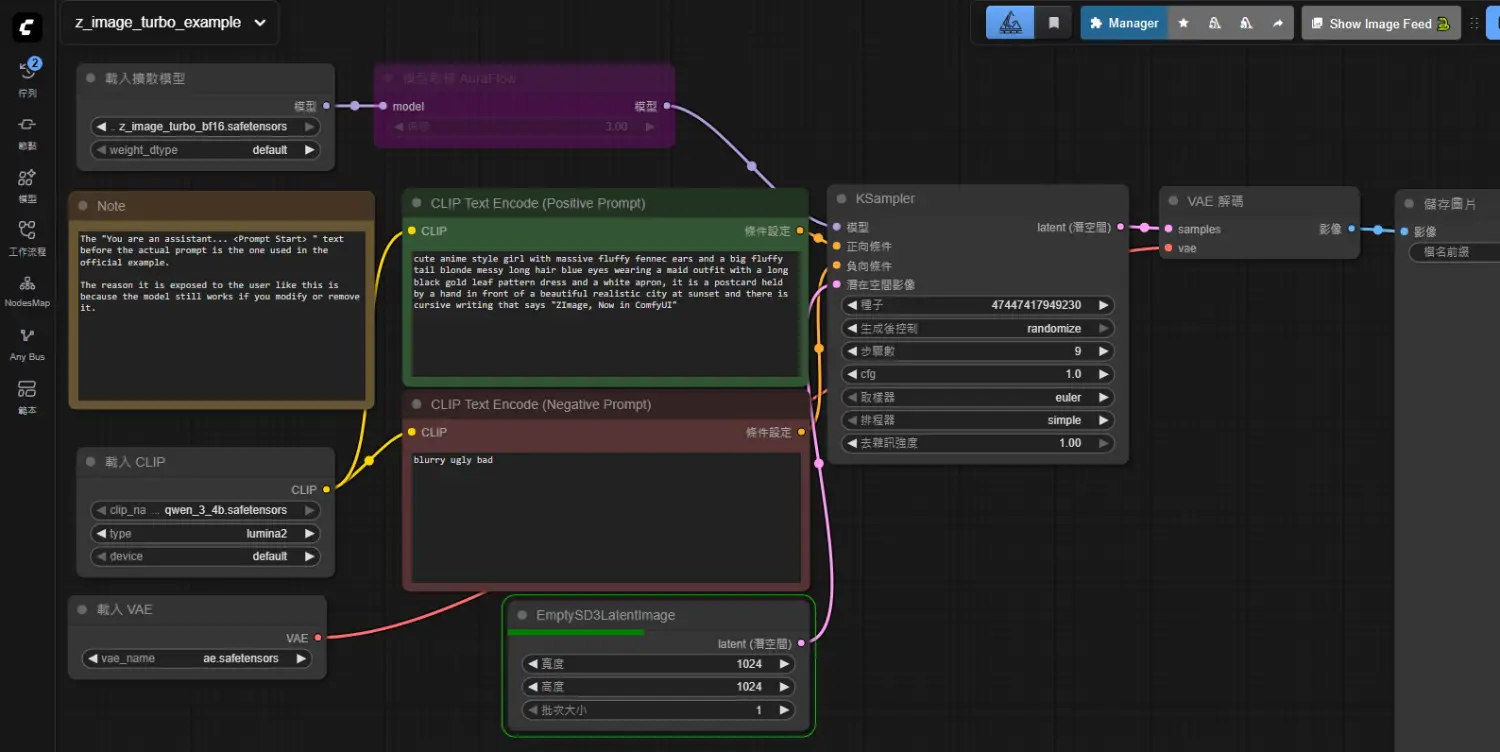
因為沒有參考圖,所以節點挺簡單的
3. 執行速度
我的環境3060 12G、批次大小2、1024x1024、steps 9
每個it約2.35秒左右,一張圖約10.5秒就完成
100%|███████████████████| 9/9 [00:21<00:00, 2.35s/it]
跟flux2比起來出圖速度根本是飛天了
所以網路上很多人是期待Z Image能成為SDXL的接班模型
除了速度快之外還有一點很重要是模型授權
Z Image是Apache-2.0 license
FLUX.2 [dev]是非商業且非生產用途的授權(Non-Commercial License v2.0)
最後還有一點NFSW...中國模型xd
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 220.129.18.149 (臺灣)
※ 文章網址: https://www.ptt.cc/bbs/AI_Art/M.1764448896.A.1D9.html
※ 發信站: 批踢踢實業坊(ptt.cc)
※ 轉錄者: avans (220.129.18.149 臺灣), 11/30/2025 04:55:41
※ 編輯: avans (42.79.138.114 臺灣), 11/30/2025 05:11:37
推
11/30 08:13,
7月前
, 1F
11/30 08:13, 1F
推
11/30 08:21,
7月前
, 2F
11/30 08:21, 2F
推
11/30 08:33,
7月前
, 3F
11/30 08:33, 3F
ComfyUI-GGUF作者已更新節點包
現在CLIPLoader (GGUF)支援載入量化的Mistral-Small語言模型
例如我測試底下權重,可順利載入
Mistral-Small-3.2-24B-Instruct-2506-IQ4_XS.gguf
https://huggingface.co/unsloth/Mistral-Small-3.2-24B-Instruct-2506-GGUF
※ 編輯: avans (111.241.69.142 臺灣), 11/30/2025 11:18:28
剛剛在C站看到有人建立了圖生圖流程
https://i.meee.com.tw/OqplQJR.png
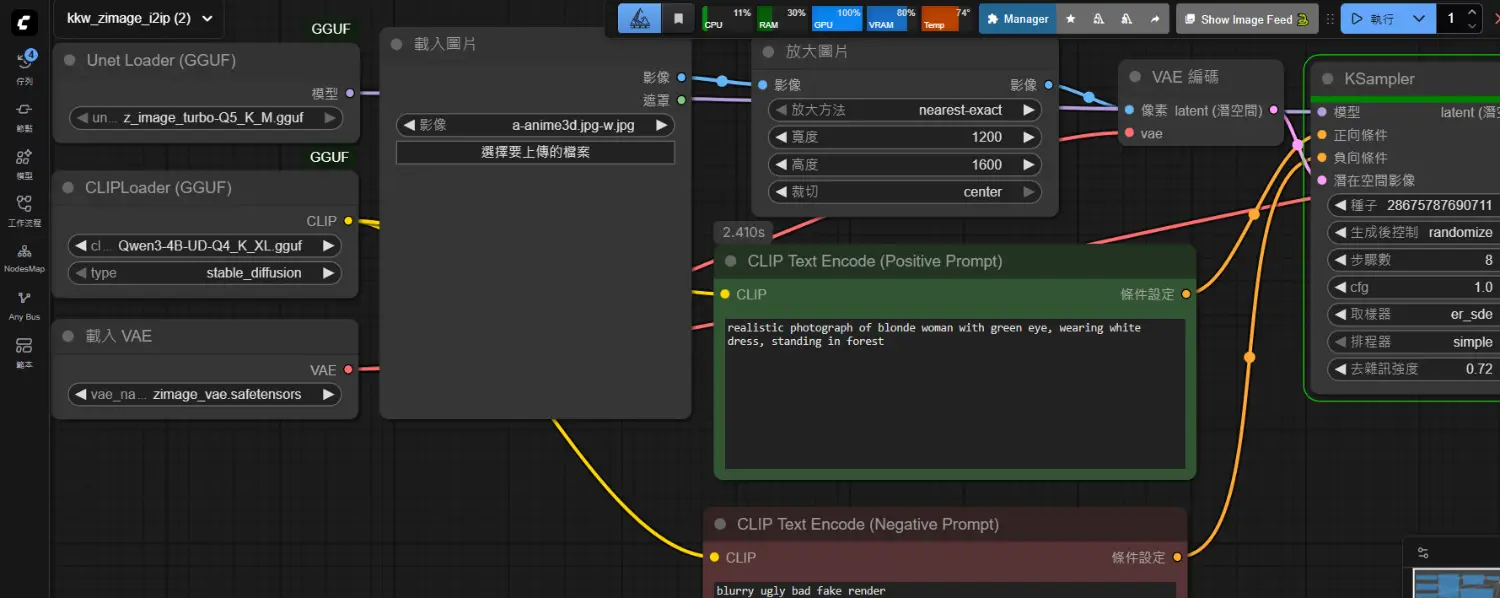
https://civitai.com/models/2171626?modelVersionId=2445484
這好像就是標準的圖生圖方式
將原本的EmptySD3LatentImage節點移除
改為載入圖片(LoadImage) => 放大圖片(ImageScale) =>
VAE 編碼 => 成為淺在空間影像 => KSampler
因為Z-Image-Turbo模型
畢竟只在t2i訓練過
i2i結果可能不如預期
還是要等Z-Image-Edit
不過還是可玩玩看
作者建議在KSampler的Denoise中
設置 0.4 到 0.74 之間
越低越可保留原始圖片樣貌
※ 編輯: avans (111.241.69.142 臺灣), 11/30/2025 14:15:23
C_Chat 近期熱門文章

28
45

PTT動漫區 即時熱門文章
6
33
