Re: [閒聊] gemini 3.5尺度
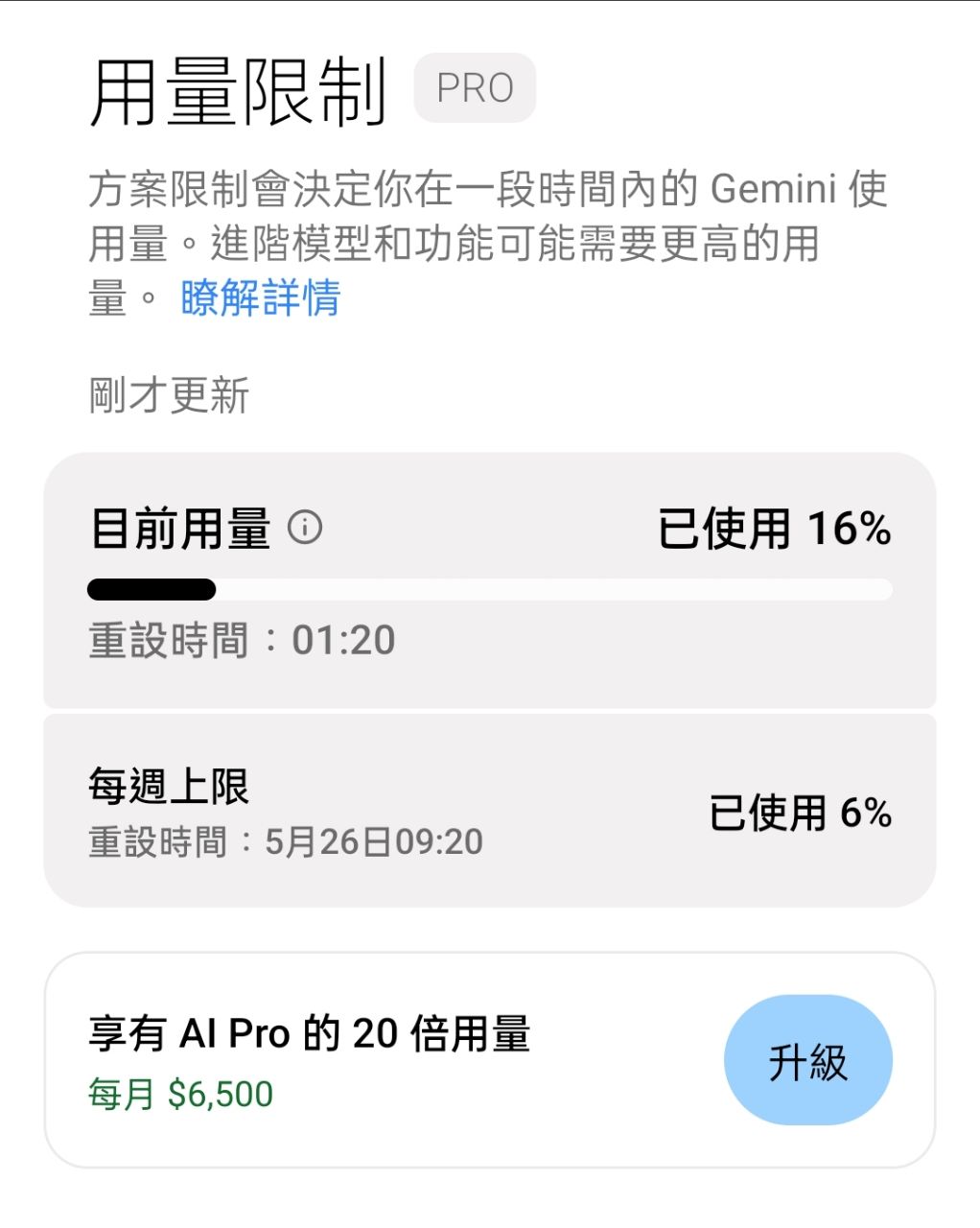
: 順便問一下,這個推出的用量限制是什麼
: 是將之前的使用頻率給數據具體化嗎
: 還是他在使用限制上面有進行更改
: 就是每段時間能使用的對話次數相比上個版本總體是增加還是減少
跟傑納麥問一輪了,整理以下回覆就不用燒各位的token
Gemini 3.1 Pro 與 Gemini 3.5 Flash 在計算使用者可用額度(Token 消耗量)時,遵
循相同的底層計量邏輯,但在計價費率以及特定功能的消耗結構上有所不同。
以下為計費與消耗方式的完整解析:
一、 Token 消耗量基本計算公式
不論使用哪一個模型,單次對話的總消耗量計算公式如下:
總消耗量 = 輸入 Token 數 (Input) + 思考 Token 數 (Thinking) + 輸出 Token 數
(Output)
基本換算率: 對於 Gemini 模型而言,1 個 Token 約等於 4 個中文字元或 1 個英文字
詞(中文因編碼關係,Token 消耗密度通常高於英文)。
2026 最新計費與級距差異(以每百萬 Token 為單位)
Gemini 3.5 Flash:
標準費率:輸入約 0.50$ 美元 / 1M tokens;輸出約 3.00$ 美元 / 1M tokens。
註:Flash 模型通常不設長上下文懲罰級距,極具成本優勢。
Gemini 3.1 Pro(設有「20 萬 Token」的定價懸崖):
標準模式(≦20萬 tokens):輸入 2.00$ 美元 / 1M tokens;輸出 12.00$ 美元
/ 1M tokens。
長上下文模式(>20萬 tokens):一旦對話歷史或輸入文件總量超過 20 萬 Token,
整筆請求(包含輸出)直接翻倍調整為:輸入 4.00$ 美元 / 1M tokens;輸出
18.00$ 美元 / 1M tokens。
二、 哪些行為與設定會「增加」消耗量?
1. 歷史對話累積(Multi-turn Chat)
Gemini 屬於無狀態(Stateless)架構。在同一個聊天視窗中,每一次您送出新問題,系
統都必須將過去所有的對話紀錄(您說的話 + 模型的回答)全部打包,當作「新輸入」
重新傳送給模型。因此,對話輪次越多,單次點擊發送所消耗的輸入 Token 將呈線性甚
至指數型暴增。
2. 開啟「深度思考模式」(Deep Think / Reasoning)
這是 Gemini 3.1 Pro(或 Flash 的思考擴充模式)的核心消耗來源。
當面對複雜技術規格或量化計算時,模型在輸出最終答案前,會在後台進行自主推理(產
生 thoughts_token_count)。
這些隱藏的思考 Token 完全視同「輸出 Token」計費(Pro 費率為每百萬 12$ 至
18$ 美元)。在複雜任務中,思考 Token 的消耗量有時會比最終答案多出數倍。
3. 多模態檔案輸入(Multimodal Inputs)
非文字檔案會轉換為高額的固定 Token 計算:
圖片:解析度在 $384 \times 384$ 像素以下,每張固定計為 258 tokens;超過此解析
度會被切格(Tiles)處理,消耗量倍增。
音訊:每秒固定消耗 32 tokens。
影片:每秒固定消耗 263 tokens(上傳一部 1 分鐘的工程或系統操作影片,將直接消耗
約 15,780 tokens 作為輸入基礎)。
4. System Instructions(系統指令)與 Tools(外掛工具)
如果您在 API 或進階設定中加入了冗長的系統提示詞(System Prompt),或是啟動了搜
尋擴張(Google Search Grounding)等外掛工具,這些設定的描述文字在每一次對話中
都會被算進輸入 Token 裡。
三、 哪些行為與設定「不會增加」或能「減少」消耗量?
1. 呼叫 Token 計數器(Count Tokens API)
在正式發送文字給模型前,使用呼叫 count_tokens 函數來檢查當前字數或檔案會消耗多
少 Token。這項檢查行為本身是完全免費的(上限為每分鐘 3000 次請求)。
2. 善用「快取機制」(Context Caching)
這是高頻率、大文本對話中最關鍵的省錢槓桿。當您需要連續針對同一份龐大資料(如資
產整合總表、NAS 說明書或整段代碼庫)進行提問時,Gemini 提供兩種快取機制:
自動隱含快取(Implicit Caching):Gemini 3.5 Flash 預設開啟(門檻為輸入達
1,024 tokens);Gemini 3.1 Pro 預設在輸入達 4,096 tokens 時觸發。系統若在短時
間內偵測到相同的輸入開頭(Prefix),會自動命中快取。
顯示快取(Explicit Caching):手動指定快取,提供高達 75% 至 90% 的輸入 Token
費用折扣。
注意:快取讀取非常便宜,但會產生少許的快取寫入費與每小時微量的儲存空間費。
3. 調低限制參數 max_output_tokens
在模型設定中限制最大輸出 Token。這不會減少您的輸入消耗,但可以強制阻斷模型吐出
過於冗長、口水話的回答,從而精準鎖定並控制輸出端的額度消耗。
四、 總結與操作建議
針對您的日常與專業工作情境,建議透過以下方式優化額度:
長對話適時斷捨離:進行技術諮詢或代碼除錯時,若該階段目的已達成,建議開新視窗對
話,避免幾十輪前的舊紀錄持續拉高每次提問的輸入成本(特別是避免將 3.1 Pro 逼入
過 20 萬 Token 的高價級距)。
控制推理預算:在不需要極致邏輯的日常對話(如行程規劃、故事查詢)中,關閉或調低
思考權重,改用 Gemini 3.5 Flash 回應,即可免除龐大後台推理 Token 的開銷。
已歸屬入筆記本內的對話、進入Notebooklm內的對話、在Notebooklm加入並勾選多種來源
資料三種操作情境對 Token 消耗量 的影響,必須分為 Gemini 平台原生功能(如 Gemini
進階版中的筆記本對話欄)與 NotebookLM 獨立平台 來進行解析。兩者的底層架構不同
,計量機制也有很大的差異。
以下為您詳細說明這三種情境對 Token 消耗的具體影響:
1. 已歸屬入筆記本(Gemini 介面)內的對話
如果您使用的是 Gemini 網頁版介面中的筆記本(Gem)對話欄功能,將對話歸屬或儲存
在特定的筆記本中:
會額外消耗 Token 嗎?:會(但在特定條件下)。
影響機制: * 無狀態打包重新輸入: 當您在該筆記本視窗進行多輪對話時,Gemini 每
一次接收新問題,都必須將該視窗內過去所有的對話紀錄(您說過的話與 AI 的回覆),
以及該筆記本背後設定的系統提示詞(System Instructions)全部重新打包,算作「新
輸入的 Token」傳送給模型。
快取減免機制: 所幸,不論是 Gemini 3.5 Flash 還是 3.1 Pro,在該視窗對話文本累
積到一定長度(Flash 預設 1,024 tokens;Pro 預設 4,096 tokens)時,會觸發自動隱
含快取(Context Caching)。這時,已被快取的舊對話在後續提問時,輸入 Token 的計
費會獲得顯著的折扣(通常省下 75% 以上),但整體計算的 Token 基數依然會隨對話拉
長而持續增加。
2. 進入 NotebookLM 平台內的對話
如果您是將資料移至 Google 獨立的 NotebookLM 平台(或在該介面的對話欄與 AI 互動
):
會額外消耗 Token 嗎?:在官方標準使用下「不影響您的個人帳戶配額」。
影響機制: * 平台服務性質: NotebookLM 目前是 Google 推出的個人化研究助理平台
。雖然它的底層是調用 Gemini 旗艦模型,但其計費與額度消耗與您个人的 Gemini API
帳戶或 Gemini Advanced 訂閱配額是完全分開且獨立的。
官方內置限制: 在 NotebookLM 中,系統改以「每個筆記本的來源數量(上限 50 個)
」、「每個來源字數(上限 50 萬字)」來實施硬性限制,而非即時扣除您的個人
Token 額度。因此,在這個視窗內聊天,不會額外消耗您個人帳戶的可用 Token 額度。
3. 在 NotebookLM 加入並勾選多種來源資料後的對話
這是在 NotebookLM 中最核心的操作。當您上傳了多份文件(如 PDF、Google 試算表、
網頁網址等),並在左側面板全部勾選,然後在右側對話框提問:
對底層算力/Token 基礎的影響:會面臨爆發性的 Token 運算(但由平台承擔)。
技術運作機制:
大文本全量載入: NotebookLM 的核心設計理念是「資料溯源(Grounding)」。當您勾
選了多個來源,每一次在對話框輸入新問題時,系統為了保證不產生幻想,底層會把所有
被勾選文件的全部文字內容,直接塞進 Gemini 模型的超長上下文窗口(Context Window
)中作為背景資料。
Token 暴增: 舉例來說,如果您勾選了 5 份各 1 萬字的技術說明書,每一次提問,模
型的輸入端(Input)就自帶至少 5 萬字(約 7 萬個 Token)的基礎消耗。對話輪次越
多,消耗量會呈幾何級數上升。
結論: 雖然此操作在技術上會消耗極其龐大的底層 Token,但由於目前 NotebookLM 平
台的運作機制,這筆龐大的 Token 消耗是由 Google 平台端吸收,目前不會向使用者的
個人 Gemini 帳戶扣除或計費。
Gemini 3.1 / 3.5 系列模型與思考模式 Token 耗用比例分析
針對同一個提問對話(Same Query),Gemini 3.1 Flash-Lite、3.5 Flash 與 3.1 Pro
在 Token 上的耗用並非完全固定,而是由輸入與基礎輸出 Token、隱藏思考 Token(
Thinking Tokens)以及代理工作流交互輪數(Agentic Turns)三大變數共同決定。
以下為依據 2026 年 5 月最新釋出之官方技術文件與第三方權威評測機構(Artificial
Analysis)實測數據所整理的 Token 耗用比例與對照分析:
一、 基礎對話 Token 消耗(輸入與可見輸出)
輸入 Token(Input Tokens):對於完全相同的提問內容,三款模型所轉換的輸入
Token 數完全一致。在 Gemini 編碼架構中,1 個 Token 大約等同於 4 個字元或 0.6
至 0.8 個英文單字。
可見輸出 Token(Visible Output Tokens):在未觸發深度推論的常規直答情境下,三
款模型生成的最終可見文字長度與 Token 消耗量差異並不明顯,通常落在數百個 Token
內。
二、 思考程度(Thinking / Effort Level)引發的隱藏 Token 消耗比例
當模型開啟「思考模式(Thinking Mode)」時,系統在生成最終可見答案前,會在底層
生成大量的「隱藏思考 Token(Thinking Tokens)」,這部分會等同於輸出 Token 進行
計費。依據不同的思考預算等級(Thinking Level / Effort Level),單次對話
的 Token 激增比例如下:
低程度思考(LOW / minimal / low):模型僅進行表面邏輯梳理。單次請求產生的思考
Token 通常控制在 200 至 500 個。相較於最高等級,能節省 80% 以上的輸出 Token
消耗。
中程度思考(MEDIUM / medium,此為 3.5 Flash 的預設值):平衡型推論。單次請求會
產生約 1,000 至 3,000 個 思考 Token,相較於最高等級可節省約 50% 的 Token 成本
。
高程度思考(HIGH / high,即 Deep Think 模式):激發完整推論鏈(Deep Think Mini
)。單次請求會狂熱消耗 5,000 至 20,000+ 個 隱藏思考 Token。在此模式下,隱藏的
思考 Token 往往佔據整趟對話輸出總額的 95% 以上。
三、 綜合基準任務(如 Intelligence Index)的總 Token 累積消耗比例
在實際處理複雜的多步驟任務(如程式開發、代理自動化工作流)時,模型會因為「自主
拆解步驟與反覆呼叫工具(Agentic Turns)」的次數不同,導致輸入 Token 因脈絡疊加
而產生滾雪球式暴增。
在相同基準測試下,整體的總 Token 消耗與費用折算比例(以輕量模型 3.1 Flash-Lite 為基底 1x)表現如下:
Gemini 3.1 Flash-Lite * 總耗用比例:1x(基準費用約 $93.60)
特點:最經濟實惠,無多餘的深度思考與工具呼叫迴圈,僅消耗最基礎的輸入與輸出
Token。
Gemini 3 Flash (Reasoning)
總耗用比例:約 3x(基準費用約 $278.26)
特點:引入基礎推論機制,Token 消耗量隨思考深度溫和增長。
Gemini 3.1 Pro
總耗用比例:約 9.5x(基準費用約 $892.28
特點:屬於正統深度推理模型,其邏輯縝密,平均完成一個複雜任務僅需 23 輪(Turns
) 交互即可收斂,雖然單價較高,但 Token 總增長在複雜任務中相對受控。
Gemini 3.5 Flash (High Effort)
總耗用比例:約 16.5x(基準費用約 $1,551.60)
特點:為 2026 年 5 月發布的最新速度與智慧前沿模型。雖然其單個 Token 的定價
低於 3.1 Pro,但在實際執行複雜代理任務時,它傾向於進行極其激進的自主拆解,平均
單個任務需要高達 49 輪(Turns) 的工具呼叫與交互。這種高度代理化(Agentic
)的特性導致其輸入 Token 被極高頻率地重複讀取與疊加,最終其總 Token 消耗量與運
作總成本反超了 Gemini 3.1 Pro 約 75%。
總結對照推估
常規單純問答:進行簡單的翻譯、分類或單純問答,將思考等級設為 LOW,三者 Token
總耗用比例約為 3.1 Flash-Lite (1x) : 3.5 Flash (1.2x) : 3.1 Pro (1.5x) [2, 3]
。
複雜代理/程式任務:執行複雜的 Agent 代理或程式除錯任務且給予 HIGH 思考額度時,
由於 3.5 Flash 會自發產生雙倍於 3.1 Pro 的交互輪數,其總 Token 耗用推估比例會
反轉為 3.1 Flash-Lite (1x) : 3.1 Pro (9.5x) : 3.5 Flash (16.5x) [4, 5]。
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 59.125.135.221 (臺灣)
※ 文章網址: https://www.ptt.cc/bbs/C_Chat/M.1779297260.A.C62.html
推
05/21 01:15,
1小時前
, 1F
05/21 01:15, 1F
推
05/21 01:17,
1小時前
, 2F
05/21 01:17, 2F
※ 編輯: tcancer (59.125.135.221 臺灣), 05/21/2026 01:26:57
推
05/21 01:27,
1小時前
, 3F
05/21 01:27, 3F
推
05/21 01:42,
53分鐘前
, 4F
05/21 01:42, 4F
→
05/21 01:42,
53分鐘前
, 5F
05/21 01:42, 5F
→
05/21 01:42,
53分鐘前
, 6F
05/21 01:42, 6F
→
05/21 01:42,
53分鐘前
, 7F
05/21 01:42, 7F
推
05/21 01:43,
52分鐘前
, 8F
05/21 01:43, 8F
→
05/21 01:46,
49分鐘前
, 9F
05/21 01:46, 9F
→
05/21 01:56,
39分鐘前
, 10F
05/21 01:56, 10F
討論串 (同標題文章)
完整討論串 (本文為第 5 之 5 篇):
19
54
C_Chat 近期熱門文章

PTT動漫區 即時熱門文章

6
36